Transcription factor activity inference in bulk RNA-seq
Bulk RNA-seq yield many molecular readouts that are hard to interpret by themselves. One way of summarizing this information is by inferring transcription factor (TF) activities from prior knowledge.
In this notebook we showcase how to use decoupleR for
transcription factor activity inference with a bulk RNA-seq data-set
where the transcription factor FOXA2 was knocked out in pancreatic
cancer cell lines.
The data consists of 3 Wild Type (WT) samples and 3 Knock Outs (KO). They are freely available in GEO.
Loading packages
First, we need to load the relevant packages:
Loading the data-set
Here we used an already processed bulk RNA-seq data-set. We provide
the normalized log-transformed counts, the experimental design meta-data
and the Differential Expressed Genes (DEGs) obtained using
limma.
For this example we use limma but we could have used
DeSeq2, edgeR or any other statistical
framework. decoupleR requires a gene level statistic to perform
enrichment analysis but it is agnostic of how it was generated. However,
we do recommend to use statistics that include the direction of change
and its significance, for example the t-value obtained for
limma(t) or
DeSeq2(stat). edgeR does not return such
statistic but we can create our own by weighting the obtained logFC by
pvalue with this formula: -log10(pvalue) * logFC.
We can open the data like this:
inputs_dir <- system.file("extdata", package = "decoupleR")
data <- readRDS(file.path(inputs_dir, "bk_data.rds"))From data we can extract the mentioned information. Here
we see the normalized log-transformed counts:
# Remove NAs and set row names
counts <- data$counts %>%
dplyr::mutate_if(~ any(is.na(.x)), ~ if_else(is.na(.x),0,.x)) %>%
column_to_rownames(var = "gene") %>%
as.matrix()
head(counts)
#> PANC1.WT.Rep1 PANC1.WT.Rep2 PANC1.WT.Rep3 PANC1.FOXA2KO.Rep1 PANC1.FOXA2KO.Rep2 PANC1.FOXA2KO.Rep3
#> NOC2L 10.052588 11.949123 12.057774 12.312291 12.139918 11.494205
#> PLEKHN1 7.535115 8.125993 8.714880 8.048196 8.290154 8.621239
#> PERM1 6.281242 6.424582 6.589668 6.293285 6.486136 6.775344
#> ISG15 10.938252 11.469081 11.425415 11.549986 11.371464 11.178157
#> AGRN 6.956335 7.196108 7.522550 7.061549 7.485534 7.071555
#> C1orf159 9.546224 9.788721 9.794589 9.850830 9.988069 9.965357The design meta-data:
design <- data$design
design
#> # A tibble: 6 × 2
#> sample condition
#> <chr> <chr>
#> 1 PANC1.WT.Rep1 PANC1.WT
#> 2 PANC1.WT.Rep2 PANC1.WT
#> 3 PANC1.WT.Rep3 PANC1.WT
#> 4 PANC1.FOXA2KO.Rep1 PANC1.FOXA2KO
#> 5 PANC1.FOXA2KO.Rep2 PANC1.FOXA2KO
#> 6 PANC1.FOXA2KO.Rep3 PANC1.FOXA2KOAnd the results of limma, of which we are interested in
extracting the obtained t-value and p-value from the contrast:
# Extract t-values per gene
deg <- data$limma_ttop %>%
select(ID, logFC, t, P.Value) %>%
filter(!is.na(t)) %>%
column_to_rownames(var = "ID") %>%
as.matrix()
head(deg)
#> logFC t P.Value
#> RHBDL2 -1.823940 -12.810588 3.030276e-06
#> PLEKHH2 -1.568830 -10.794453 9.932046e-06
#> HEG1 -1.725806 -9.788112 1.939734e-05
#> CLU -1.786200 -9.761618 1.975813e-05
#> FHL1 2.087082 8.950191 3.552199e-05
#> RBP4 -1.728960 -8.529074 4.904579e-05CollecTRI network
CollecTRI is a comprehensive resource containing a curated collection of TFs and their transcriptional targets compiled from 12 different resources. This collection provides an increased coverage of transcription factors and a superior performance in identifying perturbed TFs compared to our previous DoRothEA network and other literature based GRNs. Similar to DoRothEA, interactions are weighted by their mode of regulation (activation or inhibition).
For this example we will use the human version (mouse and rat are
also available). We can use decoupleR to retrieve it from
OmniPath. The argument split_complexes keeps
complexes or splits them into subunits, by default we recommend to keep
complexes together.
net <- get_collectri(organism='human', split_complexes=FALSE)
#> Warning in OmnipathR::import_tf_mirna_interactions(genesymbols = TRUE, resources = "CollecTRI", : 'OmnipathR::import_tf_mirna_interactions' is deprecated.
#> Use 'tf_mirna' instead.
#> See help("Deprecated")
net
#> # A tibble: 43,159 × 3
#> source target mor
#> <chr> <chr> <dbl>
#> 1 ESR1 MAPK8 1
#> 2 JUN MAPK8 1
#> 3 NR1I3 CYP2B6 1
#> 4 CEBPG IVL 1
#> 5 MAFK HBB 1
#> 6 NFE2L3 HBB 1
#> 7 TP53 ACTA1 1
#> 8 TP53 BCL2 -1
#> 9 PHOX2A DBH 1
#> 10 STAT4 IL12B 1
#> # ℹ 43,149 more rowsActivity inference with Univariate Linear Model (ULM)
To infer TF enrichment scores we will run the Univariate Linear Model
(ulm) method. For each sample in our dataset
(mat) and each TF in our network (net), it
fits a linear model that predicts the observed gene expression based
solely on the TF’s TF-Gene interaction weights. Once fitted, the
obtained t-value of the slope is the score. If it is positive, we
interpret that the TF is active and if it is negative we interpret that
it is inactive.
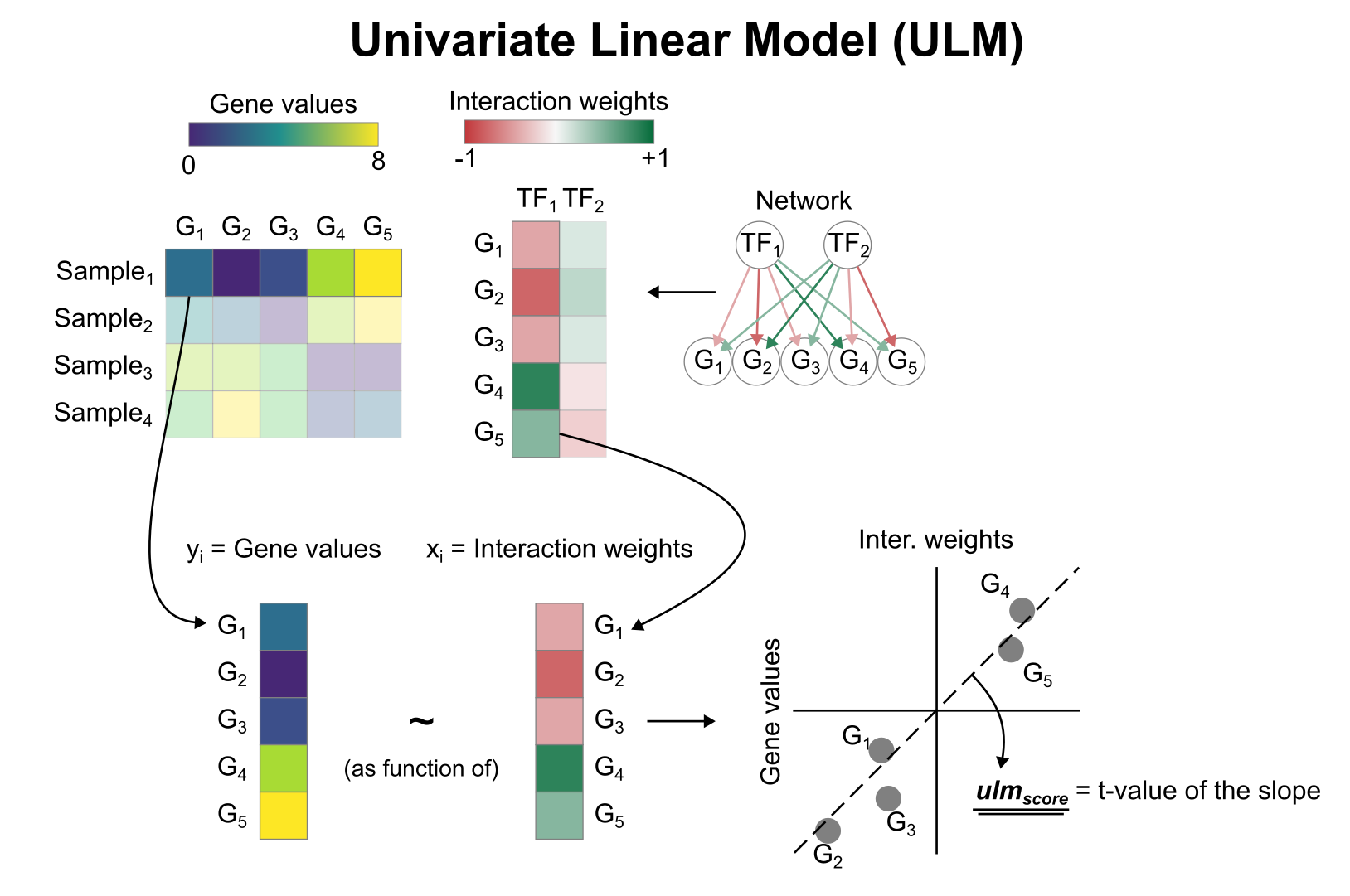
To run decoupleR methods, we need an input matrix
(mat), an input prior knowledge network/resource
(net), and the name of the columns of net that we want to
use.
# Run ulm
sample_acts <- run_ulm(mat=counts, net=net, .source='source', .target='target',
.mor='mor', minsize = 5)
sample_acts
#> # A tibble: 3,480 × 5
#> statistic source condition score p_value
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 ulm ABL1 PANC1.FOXA2KO.Rep1 -0.428 0.669
#> 2 ulm ABL1 PANC1.FOXA2KO.Rep2 -0.104 0.917
#> 3 ulm ABL1 PANC1.FOXA2KO.Rep3 0.335 0.738
#> 4 ulm ABL1 PANC1.WT.Rep1 0.142 0.887
#> 5 ulm ABL1 PANC1.WT.Rep2 -0.344 0.731
#> 6 ulm ABL1 PANC1.WT.Rep3 -0.523 0.601
#> 7 ulm AHR PANC1.FOXA2KO.Rep1 1.58 0.113
#> 8 ulm AHR PANC1.FOXA2KO.Rep2 1.70 0.0885
#> 9 ulm AHR PANC1.FOXA2KO.Rep3 1.85 0.0640
#> 10 ulm AHR PANC1.WT.Rep1 1.38 0.169
#> # ℹ 3,470 more rowsVisualization
From the obtained results we will observe the most variable activities across samples in a heat-map:
n_tfs <- 25
# Transform to wide matrix
sample_acts_mat <- sample_acts %>%
pivot_wider(id_cols = 'condition', names_from = 'source',
values_from = 'score') %>%
column_to_rownames('condition') %>%
as.matrix()
# Get top tfs with more variable means across clusters
tfs <- sample_acts %>%
group_by(source) %>%
summarise(std = sd(score)) %>%
arrange(-abs(std)) %>%
head(n_tfs) %>%
pull(source)
sample_acts_mat <- sample_acts_mat[,tfs]
# Scale per sample
sample_acts_mat <- scale(sample_acts_mat)
# Choose color palette
palette_length = 100
my_color = colorRampPalette(c("Darkblue", "white","red"))(palette_length)
my_breaks <- c(seq(-3, 0, length.out=ceiling(palette_length/2) + 1),
seq(0.05, 3, length.out=floor(palette_length/2)))
# Plot
pheatmap(sample_acts_mat, border_color = NA, color=my_color, breaks = my_breaks) 
We can also infer TF activities from the t-values of the DEGs between KO and WT:
# Run ulm
contrast_acts <- run_ulm(mat=deg[, 't', drop=FALSE], net=net, .source='source', .target='target',
.mor='mor', minsize = 5)
contrast_acts
#> # A tibble: 580 × 5
#> statistic source condition score p_value
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 ulm ABL1 t 1.08 0.280
#> 2 ulm AHR t 1.19 0.234
#> 3 ulm AIRE t -0.155 0.877
#> 4 ulm AP1 t 2.42 0.0154
#> 5 ulm APEX1 t 0.877 0.380
#> 6 ulm AR t -0.404 0.686
#> 7 ulm ARID1A t -0.236 0.813
#> 8 ulm ARID3A t 1.85 0.0639
#> 9 ulm ARID3B t 1.24 0.215
#> 10 ulm ARID4A t -0.0674 0.946
#> # ℹ 570 more rowsLet’s show the changes in activity between KO and WT:
# Filter top TFs in both signs
f_contrast_acts <- contrast_acts %>%
mutate(rnk = NA)
msk <- f_contrast_acts$score > 0
f_contrast_acts[msk, 'rnk'] <- rank(-f_contrast_acts[msk, 'score'])
f_contrast_acts[!msk, 'rnk'] <- rank(-abs(f_contrast_acts[!msk, 'score']))
tfs <- f_contrast_acts %>%
arrange(rnk) %>%
head(n_tfs) %>%
pull(source)
f_contrast_acts <- f_contrast_acts %>%
filter(source %in% tfs)
# Plot
ggplot(f_contrast_acts, aes(x = reorder(source, score), y = score)) +
geom_bar(aes(fill = score), stat = "identity") +
scale_fill_gradient2(low = "darkblue", high = "indianred",
mid = "whitesmoke", midpoint = 0) +
theme_minimal() +
theme(axis.title = element_text(face = "bold", size = 12),
axis.text.x =
element_text(angle = 45, hjust = 1, size =10, face= "bold"),
axis.text.y = element_text(size =10, face= "bold"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank()) +
xlab("TFs")
The TFs GLI3 and SPDEF are deactivated in KO when compared to WT, while MUC and NFKB1 seem to be activated.
We can further visualize the most differential target genes in each TF along their p-values to interpret the results. For example, let’s see the genes that are belong to SP1:
tf <- 'SP1'
df <- net %>%
filter(source == tf) %>%
arrange(target) %>%
mutate(ID = target, color = "3") %>%
column_to_rownames('target')
inter <- sort(intersect(rownames(deg),rownames(df)))
df <- df[inter, ]
df[,c('logfc', 't_value', 'p_value')] <- deg[inter, ]
df <- df %>%
mutate(color = if_else(mor > 0 & t_value > 0, '1', color)) %>%
mutate(color = if_else(mor > 0 & t_value < 0, '2', color)) %>%
mutate(color = if_else(mor < 0 & t_value > 0, '2', color)) %>%
mutate(color = if_else(mor < 0 & t_value < 0, '1', color))
ggplot(df, aes(x = logfc, y = -log10(p_value), color = color, size=abs(mor))) +
geom_point() +
scale_colour_manual(values = c("red","royalblue3","grey")) +
geom_label_repel(aes(label = ID, size=1)) +
theme_minimal() +
theme(legend.position = "none") +
geom_vline(xintercept = 0, linetype = 'dotted') +
geom_hline(yintercept = 0, linetype = 'dotted') +
ggtitle(tf)
Here blue means that the sign of multiplying the mor and
t-value is negative, meaning that these genes are
“deactivating” the TF, and red means that the sign is positive, meaning
that these genes are “activating” the TF.
Session information
#> ─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.6.0 (2026-04-24)
#> os Ubuntu 24.04.4 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language (EN)
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz Etc/UTC
#> date 2026-05-28
#> pandoc 3.8.3 @ /usr/local/bin/ (via rmarkdown)
#> quarto 1.9.37 @ /usr/local/bin/quarto
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [2] RSPM (R 4.6.0)
#> backports 1.5.1 2026-04-03 [2] RSPM (R 4.6.0)
#> bibtex 0.5.2 2026-02-03 [2] RSPM (R 4.6.0)
#> BiocManager 1.30.27 2025-11-14 [2] RSPM (R 4.6.0)
#> BiocParallel 1.47.0 2026-04-28 [2] https://bioc.r-universe.dev (R 4.6.0)
#> BiocStyle * 2.41.0 2026-04-28 [2] https://bioc.r-universe.dev (R 4.6.0)
#> bit 4.6.0 2025-03-06 [2] RSPM (R 4.6.0)
#> bit64 4.8.2 2026-05-19 [2] RSPM (R 4.6.0)
#> blob 1.3.0 2026-01-14 [2] RSPM (R 4.6.0)
#> bslib 0.11.0 2026-05-16 [2] RSPM (R 4.6.0)
#> buildtools 1.0.0 2026-05-22 [3] local (/pkg)
#> cachem 1.1.0 2024-05-16 [2] RSPM (R 4.6.0)
#> cellranger 1.1.0 2016-07-27 [2] RSPM (R 4.6.0)
#> checkmate 2.3.4 2026-02-03 [2] RSPM (R 4.6.0)
#> cli 3.6.6 2026-04-09 [2] RSPM (R 4.6.0)
#> cluster 2.1.8.2 2026-02-05 [2] RSPM (R 4.6.0)
#> codetools 0.2-20 2024-03-31 [2] RSPM (R 4.6.0)
#> cowplot 1.2.0 2025-07-07 [2] RSPM (R 4.6.0)
#> crayon 1.5.3 2024-06-20 [2] RSPM (R 4.6.0)
#> curl 7.1.0 2026-04-22 [2] RSPM (R 4.6.0)
#> data.table 1.18.4 2026-05-06 [2] RSPM (R 4.6.0)
#> DBI 1.3.0 2026-02-25 [2] RSPM (R 4.6.0)
#> decoupleR * 2.19.0 2026-04-28 [1] https://bioc.r-universe.dev (R 4.6.0)
#> deldir 2.0-4 2024-02-28 [2] RSPM (R 4.6.0)
#> digest 0.6.39 2025-11-19 [2] RSPM (R 4.6.0)
#> dotCall64 1.2 2024-10-04 [2] RSPM (R 4.6.0)
#> dplyr * 1.2.1 2026-04-03 [2] RSPM (R 4.6.0)
#> evaluate 1.0.5 2025-08-27 [2] RSPM (R 4.6.0)
#> farver 2.1.2 2024-05-13 [2] RSPM (R 4.6.0)
#> fastDummies 1.7.6 2026-04-22 [2] RSPM (R 4.6.0)
#> fastmap 1.2.0 2024-05-15 [2] RSPM (R 4.6.0)
#> fastmatch 1.1-8 2026-01-17 [2] RSPM (R 4.6.0)
#> fgsea 1.39.0 2026-04-28 [2] https://bioc.r-universe.dev (R 4.6.0)
#> fitdistrplus 1.2-6 2026-01-24 [2] RSPM (R 4.6.0)
#> fs 2.1.0 2026-04-18 [2] RSPM (R 4.6.0)
#> future 1.70.0 2026-03-14 [2] RSPM (R 4.6.0)
#> future.apply 1.20.2 2026-02-20 [2] RSPM (R 4.6.0)
#> generics 0.1.4 2025-05-09 [2] RSPM (R 4.6.0)
#> ggplot2 * 4.0.3 2026-04-22 [2] RSPM (R 4.6.0)
#> ggrepel * 0.9.8 2026-03-17 [2] RSPM (R 4.6.0)
#> ggridges 0.5.7 2025-08-27 [2] RSPM (R 4.6.0)
#> globals 0.19.1 2026-03-13 [2] RSPM (R 4.6.0)
#> glue 1.8.1 2026-04-17 [2] RSPM (R 4.6.0)
#> goftest 1.2-3 2021-10-07 [2] RSPM (R 4.6.0)
#> gridExtra 2.3 2017-09-09 [2] RSPM (R 4.6.0)
#> gtable 0.3.6 2024-10-25 [2] RSPM (R 4.6.0)
#> hms 1.1.4 2025-10-17 [2] RSPM (R 4.6.0)
#> htmltools 0.5.9 2025-12-04 [2] RSPM (R 4.6.0)
#> htmlwidgets 1.6.4 2023-12-06 [2] RSPM (R 4.6.0)
#> httpuv 1.6.17 2026-03-18 [2] RSPM (R 4.6.0)
#> httr 1.4.8 2026-02-13 [2] RSPM (R 4.6.0)
#> httr2 1.2.2 2025-12-08 [2] RSPM (R 4.6.0)
#> ica 1.0-3 2022-07-08 [2] RSPM (R 4.6.0)
#> igraph 2.3.1 2026-05-04 [2] RSPM (R 4.6.0)
#> irlba 2.3.7 2026-01-30 [2] RSPM (R 4.6.0)
#> jquerylib 0.1.4 2021-04-26 [2] RSPM (R 4.6.0)
#> jsonlite 2.0.0 2025-03-27 [2] RSPM (R 4.6.0)
#> KernSmooth 2.23-26 2025-01-01 [2] RSPM (R 4.6.0)
#> knitr 1.51 2025-12-20 [2] RSPM (R 4.6.0)
#> labeling 0.4.3 2023-08-29 [2] RSPM (R 4.6.0)
#> later 1.4.8 2026-03-05 [2] RSPM (R 4.6.0)
#> lattice 0.22-9 2026-02-09 [2] RSPM (R 4.6.0)
#> lazyeval 0.2.3 2026-04-04 [2] RSPM (R 4.6.0)
#> lifecycle 1.0.5 2026-01-08 [2] RSPM (R 4.6.0)
#> listenv 0.10.1 2026-03-10 [2] RSPM (R 4.6.0)
#> lmtest 0.9-40 2022-03-21 [2] RSPM (R 4.6.0)
#> logger 0.4.2 2026-05-10 [2] RSPM (R 4.6.0)
#> lubridate 1.9.5 2026-02-04 [2] RSPM (R 4.6.0)
#> magrittr 2.0.5 2026-04-04 [2] RSPM (R 4.6.0)
#> maketools 1.3.2 2025-01-25 [3] RSPM (R 4.6.0)
#> MASS 7.3-65 2025-02-28 [2] RSPM (R 4.6.0)
#> Matrix 1.7-5 2026-03-21 [2] RSPM (R 4.6.0)
#> matrixStats 1.5.0 2025-01-07 [2] RSPM (R 4.6.0)
#> memoise 2.0.1 2021-11-26 [2] RSPM (R 4.6.0)
#> mime 0.13 2025-03-17 [2] RSPM (R 4.6.0)
#> miniUI 0.1.2 2025-04-17 [2] RSPM (R 4.6.0)
#> nlme 3.1-169 2026-03-27 [2] RSPM (R 4.6.0)
#> OmnipathR 4.1.0 2026-04-29 [2] https://bioc.r-universe.dev (R 4.6.0)
#> otel 0.2.0 2025-08-29 [2] RSPM (R 4.6.0)
#> parallelly 1.47.0 2026-04-17 [2] RSPM (R 4.6.0)
#> patchwork * 1.3.2 2025-08-25 [2] RSPM (R 4.6.0)
#> pbapply 1.7-4 2025-07-20 [2] RSPM (R 4.6.0)
#> pheatmap * 1.0.13 2025-06-05 [2] RSPM (R 4.6.0)
#> pillar 1.11.1 2025-09-17 [2] RSPM (R 4.6.0)
#> pkgconfig 2.0.3 2019-09-22 [2] RSPM (R 4.6.0)
#> plotly 4.12.0 2026-01-24 [2] RSPM (R 4.6.0)
#> plyr 1.8.9 2023-10-02 [2] RSPM (R 4.6.0)
#> png 0.1-9 2026-03-15 [2] RSPM (R 4.6.0)
#> polyclip 1.10-7 2024-07-23 [2] RSPM (R 4.6.0)
#> prettyunits 1.2.0 2023-09-24 [2] RSPM (R 4.6.0)
#> progress 1.2.3 2023-12-06 [2] RSPM (R 4.6.0)
#> progressr 0.19.0 2026-03-31 [2] RSPM (R 4.6.0)
#> promises 1.5.0 2025-11-01 [2] RSPM (R 4.6.0)
#> purrr 1.2.2 2026-04-10 [2] RSPM (R 4.6.0)
#> R.methodsS3 1.8.2 2022-06-13 [2] RSPM (R 4.6.0)
#> R.oo 1.27.1 2025-05-02 [2] RSPM (R 4.6.0)
#> R.utils 2.13.0 2025-02-24 [2] RSPM (R 4.6.0)
#> R6 2.6.1 2025-02-15 [2] RSPM (R 4.6.0)
#> RANN 2.6.2 2024-08-25 [2] RSPM (R 4.6.0)
#> rappdirs 0.3.4 2026-01-17 [2] RSPM (R 4.6.0)
#> RColorBrewer 1.1-3 2022-04-03 [2] RSPM (R 4.6.0)
#> Rcpp 1.1.1-1.1 2026-04-24 [2] RSPM (R 4.6.0)
#> RcppAnnoy 0.0.23 2026-01-12 [2] RSPM (R 4.6.0)
#> RcppHNSW 0.7.0 2026-05-26 [2] RSPM (R 4.6.0)
#> readr 2.2.0 2026-02-19 [2] RSPM (R 4.6.0)
#> readxl 1.5.0 2026-05-16 [2] RSPM (R 4.6.0)
#> RefManageR * 1.4.0 2022-09-30 [2] RSPM (R 4.6.0)
#> reshape2 1.4.5 2025-11-12 [2] RSPM (R 4.6.0)
#> reticulate 1.46.0 2026-04-09 [2] RSPM (R 4.6.0)
#> rlang 1.2.0 2026-04-06 [2] RSPM (R 4.6.0)
#> rmarkdown 2.31 2026-03-26 [2] RSPM (R 4.6.0)
#> ROCR 1.0-12 2026-01-23 [2] RSPM (R 4.6.0)
#> RSpectra 0.16-2 2024-07-18 [2] RSPM (R 4.6.0)
#> RSQLite 3.53.1 2026-05-23 [2] RSPM (R 4.6.0)
#> Rtsne 0.17 2023-12-07 [2] RSPM (R 4.6.0)
#> rvest 1.0.5 2025-08-29 [2] RSPM (R 4.6.0)
#> S7 0.2.2 2026-04-22 [2] RSPM (R 4.6.0)
#> sass 0.4.10 2025-04-11 [2] RSPM (R 4.6.0)
#> scales 1.4.0 2025-04-24 [2] RSPM (R 4.6.0)
#> scattermore 1.2 2023-06-12 [2] RSPM (R 4.6.0)
#> sctransform 0.4.3 2026-01-10 [2] RSPM (R 4.6.0)
#> selectr 0.5-1 2025-12-17 [2] RSPM (R 4.6.0)
#> sessioninfo 1.2.3 2025-02-05 [2] RSPM (R 4.6.0)
#> Seurat * 5.5.0 2026-04-22 [2] RSPM (R 4.6.0)
#> SeuratObject * 5.4.0 2026-04-11 [2] RSPM (R 4.6.0)
#> shiny 1.13.0 2026-02-20 [2] RSPM (R 4.6.0)
#> sp * 2.2-1 2026-02-13 [2] RSPM (R 4.6.0)
#> spam 2.11-3 2026-01-08 [2] RSPM (R 4.6.0)
#> spatstat.data 3.1-9 2025-10-18 [2] RSPM (R 4.6.0)
#> spatstat.explore 3.8-1 2026-05-24 [2] RSPM (R 4.6.0)
#> spatstat.geom 3.8-1 2026-05-23 [2] RSPM (R 4.6.0)
#> spatstat.random 3.5-0 2026-05-24 [2] RSPM (R 4.6.0)
#> spatstat.sparse 3.2-0 2026-05-21 [2] RSPM (R 4.6.0)
#> spatstat.univar 3.2-0 2026-05-18 [2] RSPM (R 4.6.0)
#> spatstat.utils 3.2-3 2026-05-10 [2] RSPM (R 4.6.0)
#> stringi 1.8.7 2025-03-27 [2] RSPM (R 4.6.0)
#> stringr 1.6.0 2025-11-04 [2] RSPM (R 4.6.0)
#> survival 3.8-6 2026-01-16 [2] RSPM (R 4.6.0)
#> sys 3.4.3 2024-10-04 [2] RSPM (R 4.6.0)
#> tensor 1.5.1 2025-06-17 [2] RSPM (R 4.6.0)
#> tibble * 3.3.1 2026-01-11 [2] RSPM (R 4.6.0)
#> tidyr * 1.3.2 2025-12-19 [2] RSPM (R 4.6.0)
#> tidyselect 1.2.1 2024-03-11 [2] RSPM (R 4.6.0)
#> timechange 0.4.0 2026-01-29 [2] RSPM (R 4.6.0)
#> tzdb 0.5.0 2025-03-15 [2] RSPM (R 4.6.0)
#> utf8 1.2.6 2025-06-08 [2] RSPM (R 4.6.0)
#> uwot 0.2.4 2025-11-10 [2] RSPM (R 4.6.0)
#> vctrs 0.7.3 2026-04-11 [2] RSPM (R 4.6.0)
#> viridisLite 0.4.3 2026-02-04 [2] RSPM (R 4.6.0)
#> vroom 1.7.1 2026-03-31 [2] RSPM (R 4.6.0)
#> withr 3.0.2 2024-10-28 [2] RSPM (R 4.6.0)
#> xfun 0.57 2026-03-20 [2] RSPM (R 4.6.0)
#> XML 3.99-0.23 2026-03-20 [2] RSPM (R 4.6.0)
#> xml2 1.5.2 2026-01-17 [2] RSPM (R 4.6.0)
#> xtable 1.8-8 2026-02-22 [2] RSPM (R 4.6.0)
#> yaml 2.3.12 2025-12-10 [2] RSPM (R 4.6.0)
#> zip 2.3.3 2025-05-13 [2] RSPM (R 4.6.0)
#> zoo 1.8-15 2025-12-15 [2] RSPM (R 4.6.0)
#>
#> [1] /tmp/RtmpmMRXRi/Rinst27b4612831c1
#> [2] /github/workspace/pkglib
#> [3] /usr/local/lib/R/site-library
#> [4] /usr/lib/R/site-library
#> [5] /usr/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────